Success Story – How Inoreader Migrated From Bare-metal Servers to OpenNebula + StorPool

This will be a really long post and will get a bit technical for some people. The TLDR version is that we have made a significant infrastructure upgrades in the last few months that will allow our service to scale in the coming years without any worries of downtime and potential data loss. We’ve been able to greatly improve our capacity and flexibility thanks to the great combination of OpenNebula and StorPool. If you are tech geek like us, it might be interesting for you to read more about our journey.
Prolog
Building and maintaining a cloud RSS reader requires resources. Lots of them! Behind the deceivingly simple user interface there is a complex backend with huge datastore that should be able to fetch millions of feeds in time, store billions of articles indefinitely and make any of them available in just milliseconds – either by searching or simply by scrolling through lists. Even calculating the unread counts for millions of users is enough of a challenge that it deserves a special module for caching and maintaining. The very basic feature that every RSS reader should have – being able to filter only unread articles, requires so much resource power that it contributes to around 30% of the storage pressure on our first-tier databases.
We are using our own hardware collocated in a highly secure datacenter at Equinix, just 30 minutes away from our main office. This solution allows us to be independent in terms of our infrastructure. If something breaks, we don’t need to wait for ticket resolution somewhere. We just go there and fix it by ourselves. The Internet knows enough horror stories, like the recent 3-day outage of Cast or how the The FBI stole an Instapaper server back in 2011. We will not allow this to happen to us.
Until very recently we were using bare-metal servers to operate our infrastructure, meaning we deployed services like database and application servers directly on the operating system of the server. We were not using virtualization except for some really small micro-services and it was practically one physical server with local storage broken down into several VMs. Last year we have reached a point where we had a 48U (rack-units) rack full of servers. Here’s how it looked like in November 2017:

More than half of those servers were databases, each with its own storage. Usually 4 to 8 spinning disks in RAID-10 mode with expensive RAID controllers equipped with cache modules and BBUs. All this was required to keep up with the needed throughput.
There is one big issue with this setup. Once a database server fills up (usually at around 3TB) we buy another one and this one becomes read-only. CPUs and memory on those servers remain heavily underutilized while the storage is full.
For a long time we knew we have to do something about it, otherwise we would soon need to rent a second rack, which would have doubled our bill. The cost was not the primary concern. It just didn’t feel right to have a rack full of expensive servers that we couldn’t fully utilize because their storage was full.
Furthermore redundancy was an issue too. We had redundancy on the application servers, but for databases with this size it’s very hard to keep everything redundant and fully backed up. Two years ago we had a major incident that almost cost us an entire server with 3TB of data, holding several months worth of article data. We have completely recovered all data, but this was close.
Big changes were needed.
While the development of new features is important, we had to stop for a while and rethink our infrastructure. After some long sessions and meetings with vendors we have made a final decision:
We will completely virtualize our infrastructure and we will use OpenNebula + KVM for virtualization and StorPool for distributed storage.
Cloud Management
We have chosen this solution not only because it is practically free if you don’t need enterprise support but also because it is proven to be very effective. OpenNebula is now mature enough and has so many use cases it’s hard to ignore. It is completely open source with big community of experts and has an optional enterprise support. KVM is now used as primary hypervisor for EC2 instances in Amazon EWS. This alone speaks a lot and OpenNebula is primarily designed to work with KVM too. Our experience with OpenNebula in the past few months didn’t make us regret this decision even once.

Storage
Now a crucial part of any virtualized environment is the storage layer. You aren’t really doing anything if you are still using the local storage on your servers. The whole idea of virtualization is that your physical servers are expendable. You should be able to tolerate a server outage without any data loss or service downtime. How do you achieve that? With a separate, ultra-high performance fault-tolerant storage connected to each server via redundant 10G network.
This part is even more important than the choice of a hypervisor since it holds all our (and yours too!) data. If anything ever happens there we will be exposed. So we were very careful to select the perfect solution and there were many.
There’s EMC‘s enterprise solution, which can cost millions and uses proprietary hardware, so it’s out of our league. Also big vendors doesn’t usually play well with small clients like us. There’s a chance that we will just have to sit and wait for a ticket resolution if something breaks, which contradicts our vision.
Then there’s RedHat’s Ceph, which comes completely free of charge, but we were a bit afraid to use it since nobody at the team had the required expertise to run it in production without any doubt that in any event of a crash we will be able to recover all our data. We were on a very tight schedule with this project, so we didn’t have any time to send someone for trainings. Performance figures were also not very clear to us and we didn’t know what to expect. So we decided not to risk with it for our main datacenter. We are now using Ceph in our backup datacenter, but more on that later.
Finally there’s a one still relatively small vendor, that just so happens to be located some 15 minutes away from us – StorPool. They were recommended to us by colleagues running similar services and we had a quick kick-start meeting with them. After the meeting it was clear to us that those guys know what they are doing at the lowest possible level.
Here’s what they do in a nutshell (quote from their website):
StorPool is a block-storage software that uses standard hardware and builds a storage system out of this hardware. It is installed on the servers and creates a shared storage pool from their local drives in these servers. Compared to traditional SANs, all-flash arrays, or other storage software StorPool is faster, more reliable and scalable.
Doesn’t sound very different from Ceph, so why did we chose them? Here are just some of the reasons:
- They offer full support for a very reasonable monthly fee, saving us the need to have a trained Ceph expert onboard.
- They promise higher performance than ceph.
- They have their own OpenNebula storage addon (yeah, Ceph does too, I know)
- They are a local company and we can always pick up the phone and resolve any issues in minutes rather than hours or days like it usually ends up with big vendors.
And now the story begins…
The planning phase
So after we made our choice for virtualization it was time to plan the project. This happened in November 2017, so not very far from now. We have rented a second rack in our datacenter. The plan was to install the StorPool nodes there and gradually move servers and convert them into hypervisors. Once we move everything we will remove the old rack.
We have ordered 3 servers for the StorPool storage. Each of those servers have room for 16 hard-disks. We have only ordered half of the needed hard-disks, because we knew that once we start virtualizing servers, we will salvage a lot of drives that won’t be needed otherwise.
We have also ordered the 10G network switches for the storage network and new Gigabit switches for the regular network to upgrade our old switches. For the storage network we chose Quanta LB8. Those beasts are equipped with 48x10G SFP+ ports, which is more than enough for a single rack. For the regular Gigabit network, we chose Quanta LB4-M. They have additional 2x10G SFP+ modules, which we used to connect the two racks via optic cable.
We also ordered a lot of other smaller stuff like 10G network cards and a lot of CPUs and DDR memory. Initially we didn’t plan to upgrade the servers before converting them to hypervisors in order to cut costs. However after some benchmarking we found that our current CPUs were not up to the task. We were using mostly dual CPU servers with Intel Xeon E5-2620 (Sandy Bridge) and they were already dragging even before the Meltdown patches. After some research we chose to upgrade all servers to E5-2650 v2 (Ivy Bridge), which is a 16-core (with Hyper-threading) CPU with a turbo frequency of 3.4 GHz. We already had two of these and benchmarks showed two-fold increase in performance compared to E5-2620.
We also decided to boost all servers to 128G of RAM. We had different configurations, but most servers were having 16-64GB and only a handful were already at 128G. So we’ve made some calculations and ordered 20+ CPUs and 500+GB of memory. A big shoutout here to Michael Goodliffe from ViralVPS who provided us with great discounts so we didn’t overshoot our budget too much. DDR memory is very expensive at the moment!
After we placed all orders we had about a month before everything arrives, so we used that time to prepare what we can without additional hardware.
The preparation phase
The execution phase









As you can probably see from the pictures, everything is redundant. Each server and switch has two power supplies connected to independent circuits. Each server also has two 10G network interfaces connected to different switches so in case one fails, the other will take over. The actual storage layer has 3x redundancy, which means that we can lose two servers without any data loss!


After we had our shiny new OpenNebula cluster with StorPool storage fully working it was time to migrate the virtual machines that were still running on local storage. The guys from StorPool helped us a lot here by providing us with a migration strategy that we had to execute for each VM. If there is interest we can post the whole process in a separate post.
From here on we were gradually migrating physical servers to virtual machines. The strategy was different for each server, some of them were databases, others application and web servers. We’ve managed to migrated all of them with several seconds to no downtime at all. At first we didn’t have much space for virtual machines, since we had only two hypervisors, but at each iteration we were able to convert more and more servers at once.


Not all servers went into our OpenNebula cluster. Some were single CPU servers and some were storage-specific machines. Those went into our new backup datacenter, but more on this later.
After that each server went through a complete change. CPUs and memory were upgraded, the expensive RAID controllers were removed from the expansion slots and in their place we installed 10G network cards. Large (>2TB) hard drives were removed and smaller drives were installed just to install the OS. Thanks to a special staging room in the datacenter we didn’t have to haul them each time to our main office and back. After the servers were re-equipped, they were installed in the new rack and connected to the OpenNebula cluster. The guys from StorPool configured each server to have a connection to the storage and verified that it is ready for production use.


The first 24 leftover 2TB hard drives were immediately put to work into our StorPool cluster and the rest went into our backup datacenter.
This process was repeated several times until we ran out of servers in the old rack.

The result
In just couple of weeks of hard work we have managed to migrate everything!

In the new rack we have a total of 120TB of raw storage, 1.2TB of RAM and 336 CPU cores. Each server is connected to the network with 2x10G network interfaces.
That’s roughly 3 times the capacity and 10 times the network performance of our old setup with only half the physical servers!
The flexibility of OpenNebula and StorPool allows us to use the hardware very efficiently. We can spin up virtual machines in seconds with any combination of CPU, memory, storage and network interfaces and later we can change any of those parameters just as easy. It’s the DevOps heaven!
This setup will be enough for our needs for a long time and we have more than enough room for expansion if need arise.


Our OpenNebula cluster
We now have more than 50 virtual machines because we have split some physical servers into several smaller VMs with load balancers for better load distribution and we have allocated more than 46TB of storage.
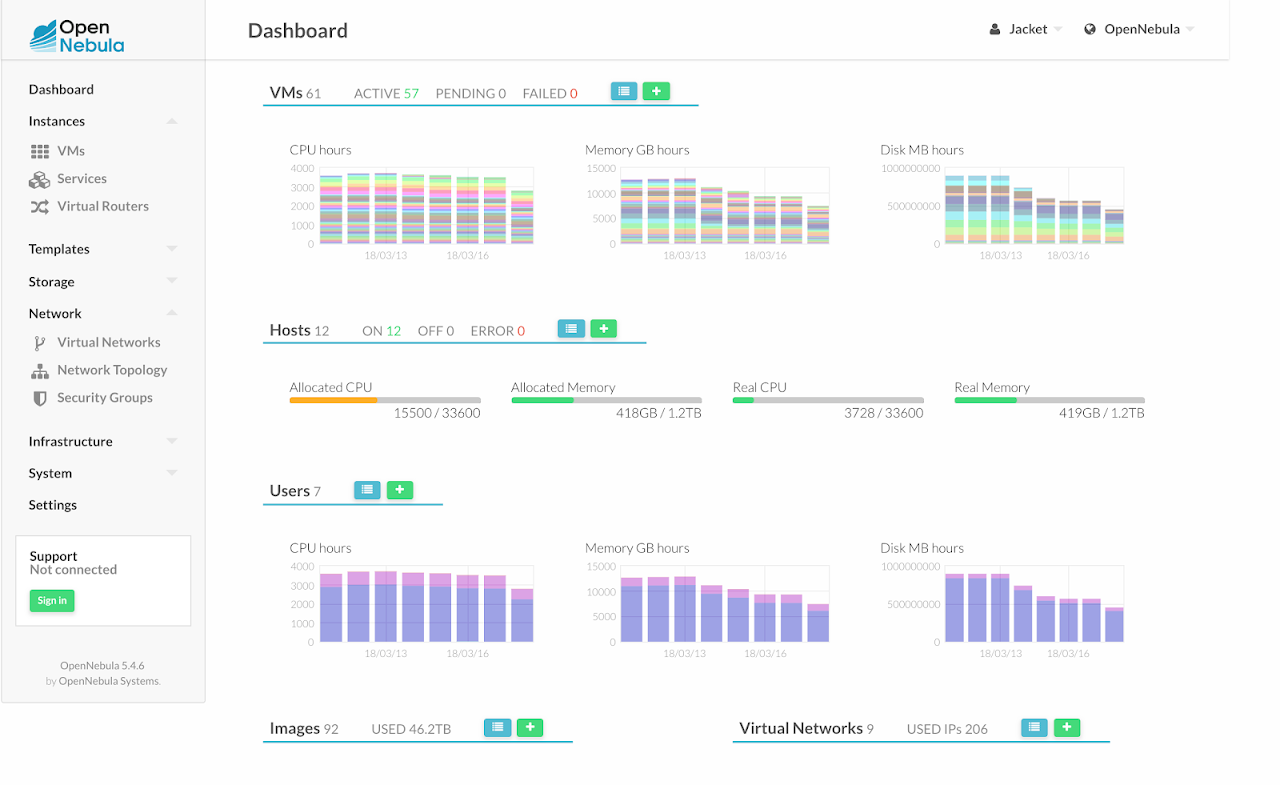
We have 12 hypervisors with plenty of resources available on each of them. All of them are using the same model CPU, which gives us the ability to use the “host=passthrough” setting of QEMU to improve VM performance without the risk of VM crash during a live migration.
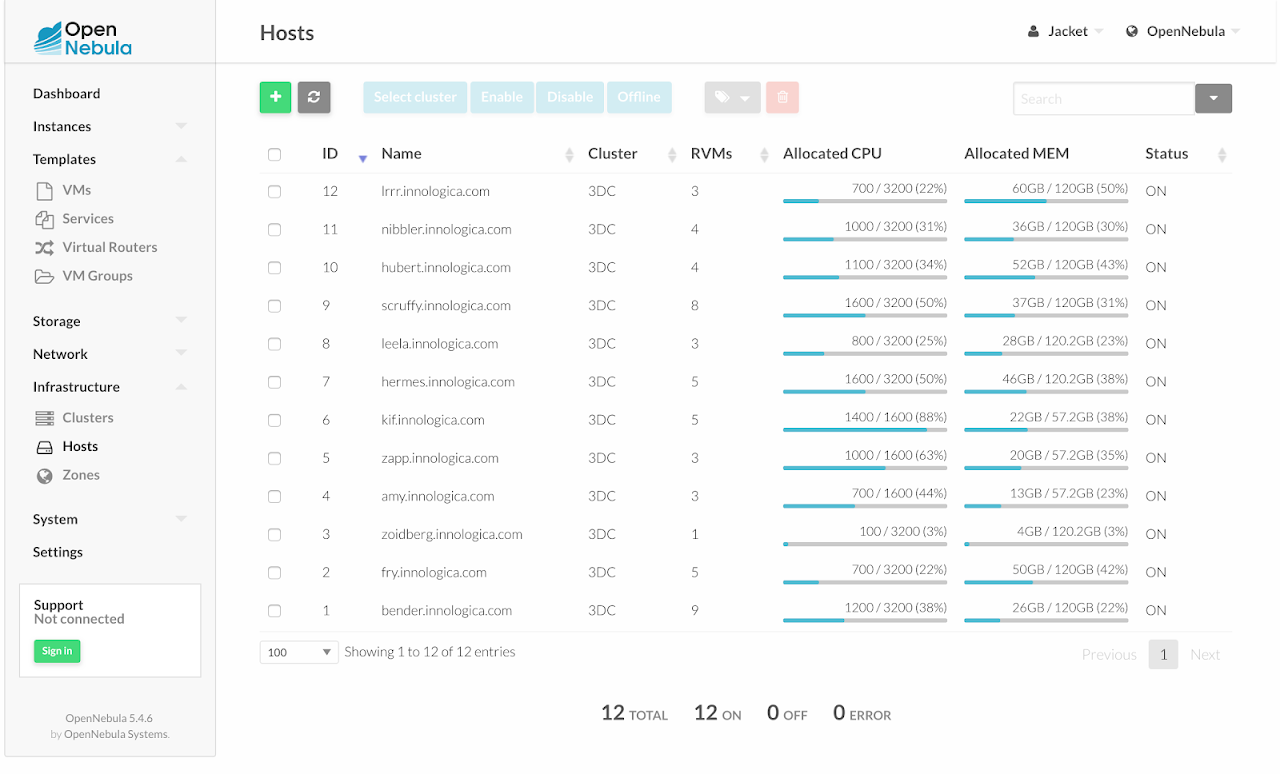
We are very happy with this setup. Whenever we need to start a new server, it only takes minutes to spin up a new VM instance with whatever CPU and memory configuration we need. If a server crashes, all VMs will automatically migrate to another server. OpenNebula makes it really easy to start new VMs, change their configurations, manage their lifecycle and even completely manage your networks and IP address pools. It just works!
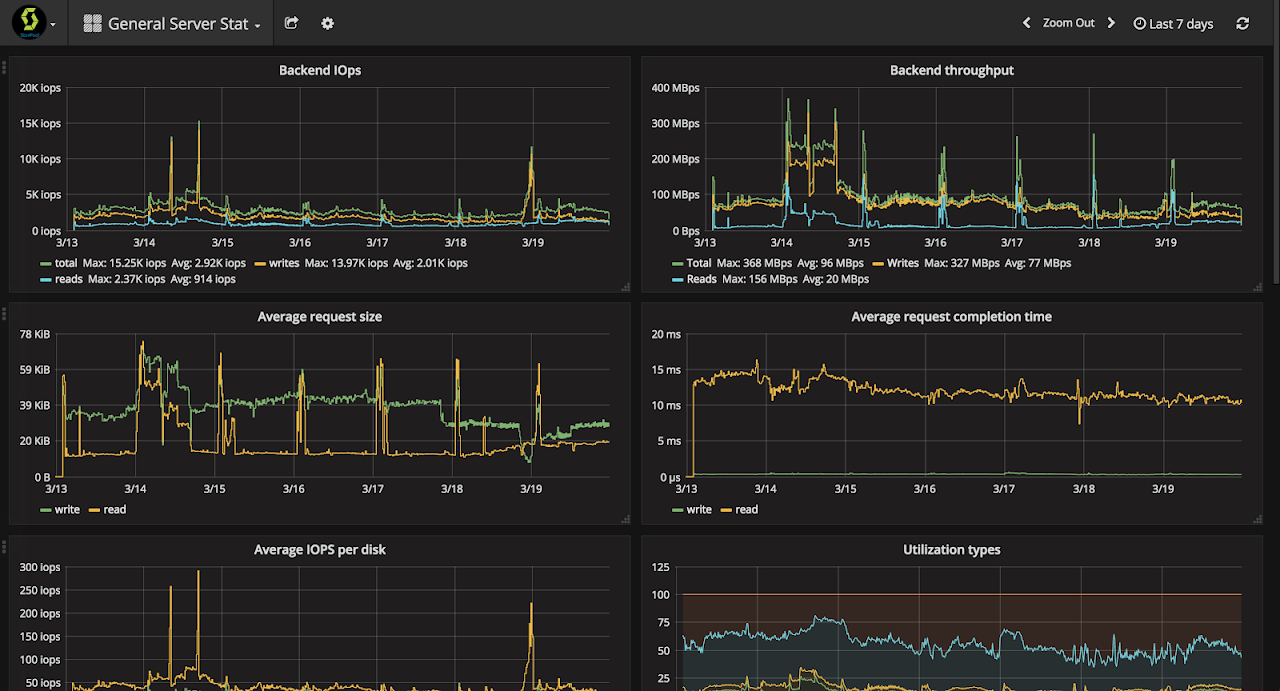
StorPool on the other hand takes care that we have all the needed IOPS at our disposal whenever we need them.
We are using Graphite + Grafana to plot some really nice graphs for our cluster.
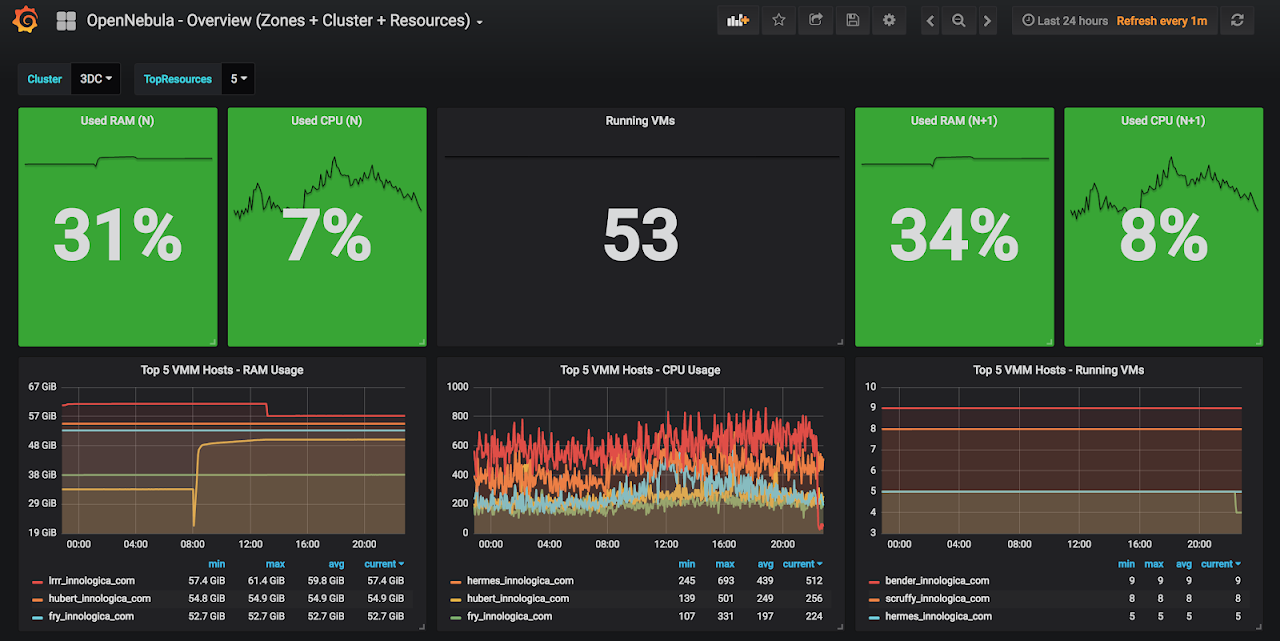
We have borrowed the solution from here. That’s what’s so great about open software!
StorPool is also using Grafana for their performance monitoring and they have also provided us with access to it, so we can get insights about what the storage is doing at the moment, which VMs are the biggest consumers, etc. This way we can always know when a VM has gone rogue and is stealing our precious IOPS.
The Black Mirror
I have mentioned a backup datacenter couple of times in this post.
Not all of our servers were good candidates for becoming hypervisors. For example some of them were not compatible with Ivy Bridge CPUs, some were thicker 2U (rack units) servers and we really wanted to have only 1U hypervisors to save rack space. Also servers are usually optimized for storage and we still had plenty of 2TB drives lying around after the migration. So we quickly put them to work!
In the basement of our office building, we have rented a room, equipped it with air conditioning and a big UPS and moved the less fortunate servers there.


Here we now have one backup server with 20TB of storage for our daily VM snapshots and database backups, 3 nodes forming a 32TB Ceph cluster for operational storage and 4 hypervisors for a second, independent OpenNebula cluster from our main one and some other lower-priority servers.
The idea is to have a fully working copy of our main datacenter that can be used in case of an emergency situation. It is intended to be a mirror for black days, so – Black Mirror. We now have all our data replicated in real time from our main data center so even in the highly unlikely event that some disaster happens there, we will still have everything off-site and we will be able to restore operations within less than an hour.
The reason we chose Ceph as a storage here is partially because we didn’t need the performance of our main datacenter, but also because we are tech nerds and we like to learn technologies, so this was the perfect opportunity.
For the geeks interested in Ceph: Each of the nodes is equipped with 2 independent MegaRaid SAS 9271-4I controllers with 1G cache modules + BBU, each controlling 4 drives. 8 drives per node (2 for OS, 6 for Ceph). Drives are exported as single-disk RAID-0’s because we wanted to use the controller caches as much as possible. This is usually a very expensive setup, but we had those controllers lying around after the main project was completed and we wanted to put them to work. We are open for suggestions here, especially JBOD vs RAID, so if you are feeling geeky, tell us what you think in the comments below.
OpenNebula works quite well with Ceph. It has a built-in support for Ceph datastores and the setup is quite straightforward and well documented, so I’m not going to repeat it here.
We have managed to plot some nice Ceph and OpenNebula dashboards in our Grafana too.
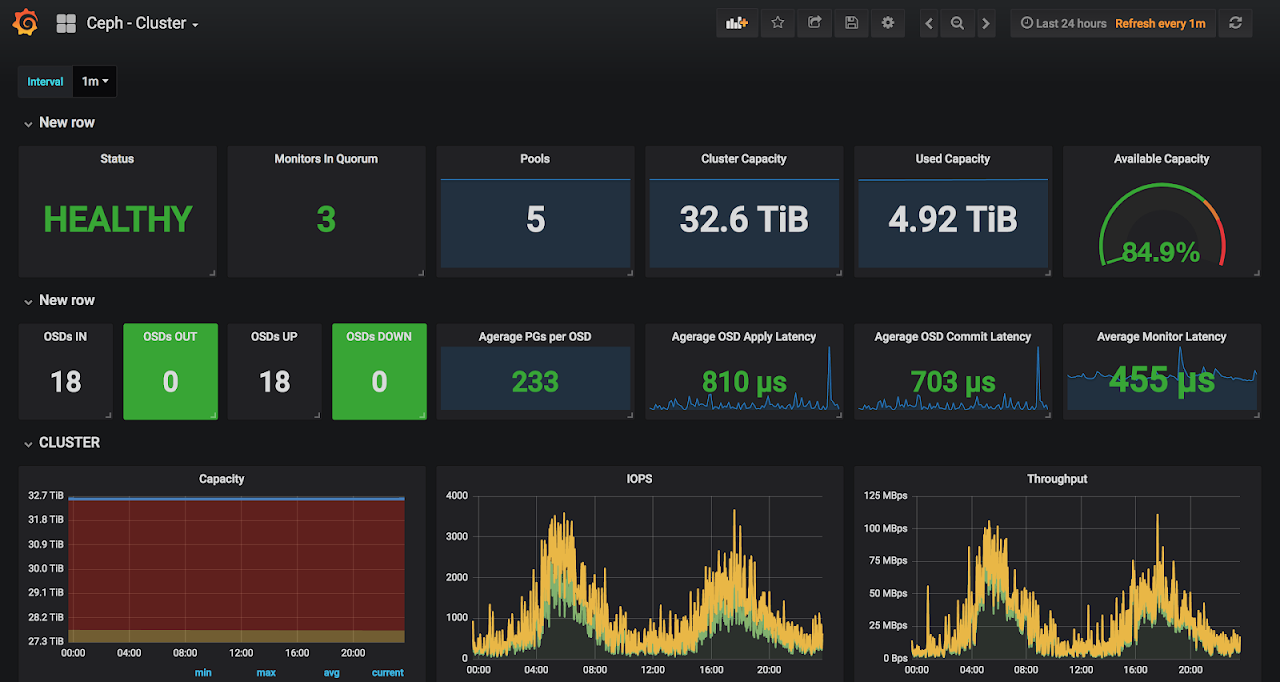
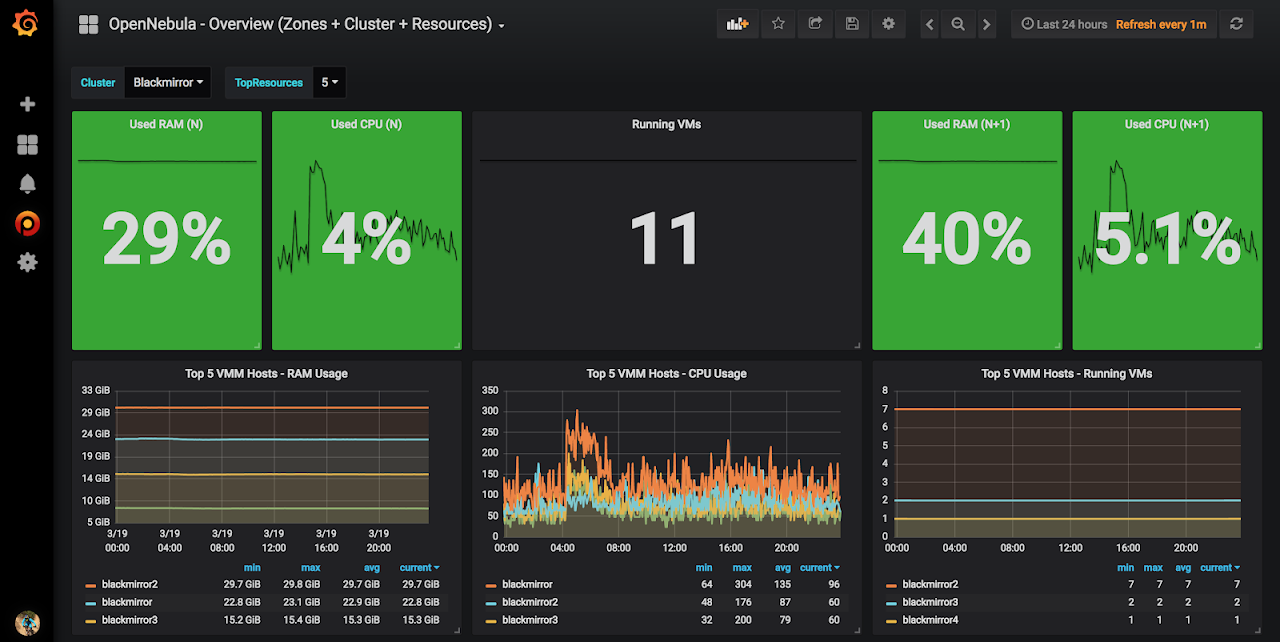
What’s left?
Epilog